Motion Matching in O3DE, a Data-Driven Animation Technique
| May 12, 2022

Motion matching is a data-driven animation technique that is gaining popularity since games like ‘The Last Of Us Part II’, ‘FIFA’, and ‘Half-Life: Alyx’ have adopted it. Users have higher expectations for animation quality including more realistic animations and a greater variety of interactions between characters and their environments. This growth in expectation resulted in increasingly complex animation graphs that became harder to maintain and more expensive to create. Motion matching is a way to animate a character in a controlled way by jumping and blending between pre-recorded animation sequences several times a second, synthesizing the animation for the character. It can be used for realistic locomotion without the need to manually create carefully timed transition points and synchronization between animation clips.
We brought motion matching to O3DE’s animation system EMotion FX as a blend tree node so that it can still be used and mixed with everything else available in the animation graph.
Motion Database
To animate a character using motion matching, we need a library of character animations such as walking slowly, running fast, narrow and wide turns, accelerating and decelerating, and many more. A large variety of movements is required so that there is a piece of animation for every situation. Kristjan Zadziuk and his team ( GDC 2016 Talk, Animation Bootcamp: Motion Matching ) gave this some structure and worked out a set of dance cards. These dance cards describe paths actors move along in a motion capture studio that capture the full range of motions for best visual results. They also minimize variations and redundant data that decrease the algorithm’s performance.
For motion matching, this collection of animation moves is referred to as the motion database. You can see a sample database of moves in the O3DE repository .
Motion Features
A smooth animation is the result of continuity. Sudden changes in position or velocity will result in unrealistic motion. We want to synthesize an animation that is fluent and matches the intention of the user’s interaction. If the user presses forward on the game-pad, it is not enough to transition to an animation sequence that results in a smooth animation while the expected direction of movement is ignored.
In order to find the best possible transition, we need data that we call features to help us. A feature is a property extracted from the animation data that is used by the motion matching algorithm to find a good match for a transition. Examples of features are the position of the feet joints, the linear or angular velocity of the knee joints, or the trajectory history and future trajectory of the root joint. We can also encode environment sensations like obstacle positions and height, the location of the sword of an enemy character, or a football’s position and velocity.
A feature’s purpose is to describe the key characteristics of the pose and the animation. Sometimes features even enhance the actual key-frame data (the local-space joint transforms) by, for example, taking the time domain into account and calculating the velocity or acceleration. They can encode a whole trajectory to describe where the given joint came from to reach the frame and the path it moves along in the near future.
| Position Feature | Velocity Feature | Trajectory Feature |
|---|---|---|
| Matches joint positions | Matches joint velocities | Matches the trajectory history and future trajectory |
 |  |  |
An interactive character in a game might walk in a different direction than in the pre-recorded animation, which makes it impossible for us to work with world-space data. Features are extracted and stored relative to a given joint, in most cases the motion extraction or root joint, and thus are in model-space. This makes the search algorithm invariant to the character location and orientation and the extracted features, e.g. a joint position or velocity translate and rotate along with the character.
Features are responsible for each of the following:
- Extract the feature values for a given frame in the motion database and store them in a feature matrix. For example, calculate the left foot joint linear velocity, convert it to relative to the root joint (model space) for frame 134 and place the XYZ components in the feature matrix starting at column 9.
- Extract the feature from the current input context/pose and fill the query vector with it. For example, calculate the linear velocity of the left foot joint of the current character pose relative-to the root joint (model space) and place the XYZ components in the feature query vector starting at position 9.
- Calculate the cost of the feature so that the motion matching algorithm can weigh it in to search for the next best matching frame. An example would be calculating the squared distance between a frame in the motion matching database and the current character pose for the left foot joint.
Feature schema
There is no set of features that best suits all scenarios. Different situations might require a different bias in the search and thus we want to be able to customize the algorithm. The feature schema is a set of features that define the criteria used in the motion matching algorithm and influences the runtime speed, memory usage, and the results of the synthesized motion.
The schema defines which features are extracted from the motion database while the actual extracted data is stored in the feature matrix. Along with the feature type, settings like the joint to extract the data from, a debug visualization color, how the residual is calculated, or a custom feature can be specified.
The more features selected by the user, the bigger the chances are that the searched and matched pose hits the expected result, but the slower the algorithm will be and the more memory it will use. The key is to use crucial and independent elements that define a pose and its movement without being too strict. The root trajectory along with the left and right foot positions and velocities have been proven to be a good start here.
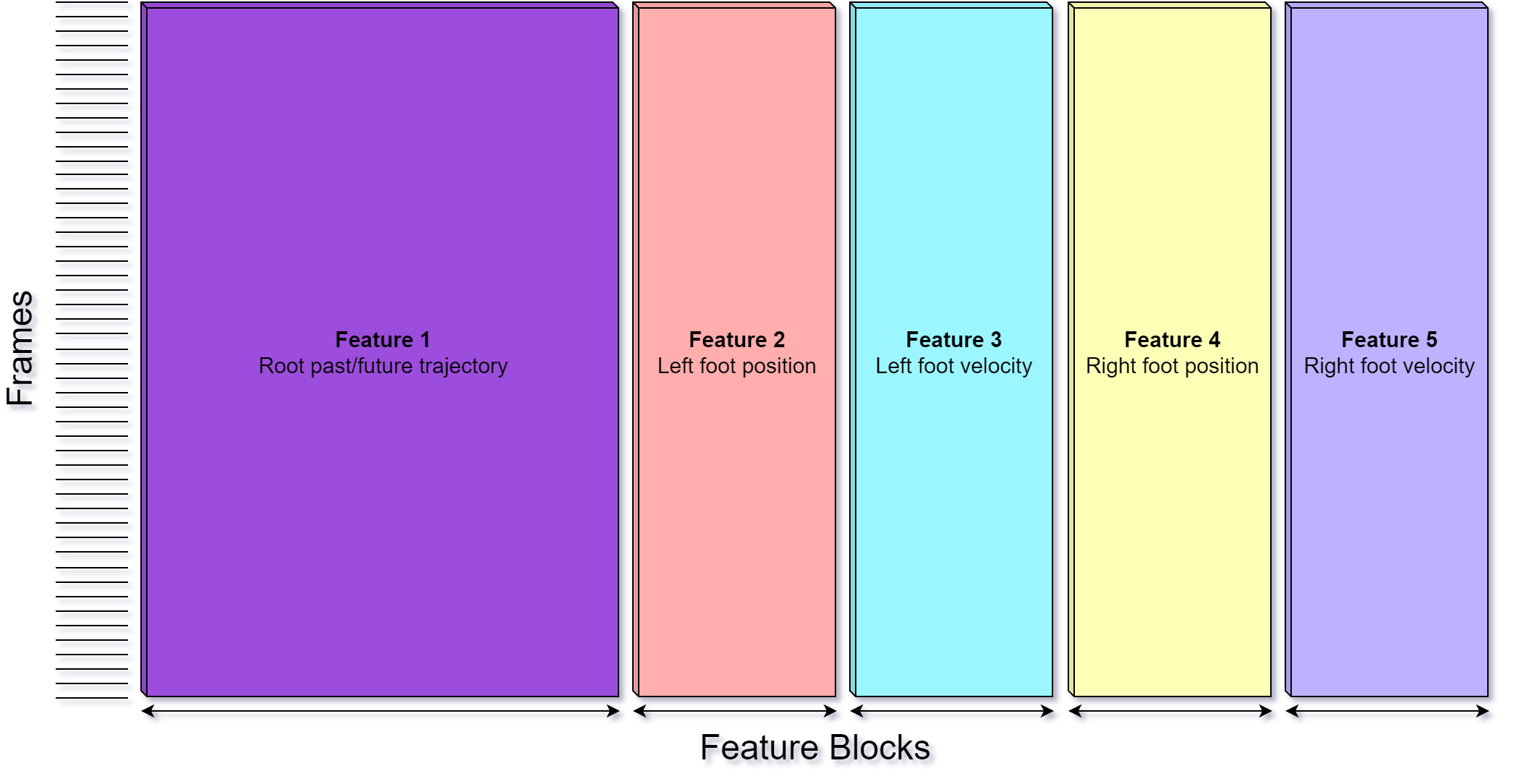
Feature matrix
We store the extracted feature values in a giant block of data, the feature matrix. The feature matrix is a NxM matrix that stores the extracted feature values for all frames in our motion database based upon a given feature schema. The feature schema defines the order of the columns and values. It is then used to identify values and find their location inside the matrix.
A 3D position feature storing XYZ values, for example, will use three columns in the feature matrix. Every component of a feature is linked to a column index, so for example, the left foot position Y value might be at column index 6. The group of values or columns that belong to a given feature is what we call a feature block. The accumulated number of dimensions for all features in the schema (while the number of dimensions might vary per feature) form the number of columns of the feature matrix.
Each row represents the features of a single frame of the motion database. As the data is commonly accessed on a per-frame basis, it is stored in row-major order for cache efficiency.
Memory usage: A motion capture database holding 1 hour of animation data together with a sample rate of 30 Hz to extract features will generate 108,000 frames. Using the default feature schema, comprising of 59 features, will result in a feature matrix holding ~6.4 million values and use ~24.3 MB of memory.
The motion matching algorithm
Now that we have all the data we need, let’s get on to the actual algorithm.
Update loop
In the majority of the game ticks, the current motion gets advanced. A few times per second, the actual motion matching search is triggered to prevent drifting too far away from the expected user input (as we would just play the recorded animation otherwise).
When a search for a better next matching frame is triggered, the current pose, including its joint velocities, gets evaluated. This pose (which we’ll call input or query pose) is used to fill the query vector. The query vector contains feature values and is compared against other frames in the feature matrix. The query vector has the same size as there are columns in the feature matrix and is similar to any other row which stores the features for a given frame in the motion database.
Using the query vector, we can find the next best matching frame in the motion database and start transitioning towards that.
In case the new best matching frame candidate is close to the time in the animation that we are already playing, we don’t do anything as we seem to be at the sweet spot in the motion database already.
Pseudo-code:
// Keep playing the current animation.
currentMotion.Update(timeDelta);
if (Is it time to search for a new best matching frame?) // We might e.g. do this 5x a second
{
// Evaluate the current pose including joint velocities.
queryPose = SamplePose(newMotionTime);
// Update the input query vector (Calculate features for the query pose)
queryValues = CalculateFeaturesFromPose(queryPose);
// Find the frame with the lowest cost based on the query vector.
bestMatchingFrame = FindBestMatchingFrame(queryValues);
// Start transitioning towards the new best matching frame in case it is not
// really close to the frame we are already playing.
if (IsClose(bestMatchingFrame, currentMotion.GetFrame()) == false)
{
StartTransition(bestMatchingFrame);
}
}
Cost function
The core question the algorithm tries to answer is: Where do we jump and transition to? The algorithm tries to find the best time in the motion database that matches the current character pose including its movements and the user input. To compare the frame candidates with each other, we use a cost function.
The feature schema defines what the cost function looks like. Every feature added to the feature schema adds to the cost. The bigger the discrepancy between the current velocity and the one from the frame candidate, the higher the penalty to the cost and the less likely the candidate is a good one to take.
This makes motion matching an optimization problem where the frame with the minimum cost is the most preferred candidate to transition to.
Searching next best matching frame
The actual search happens in two phases, a broad phase to eliminate most of the candidates followed by a narrow phase to find the actual best candidate.
1. Broad-phase (KD-tree)
A KD-tree is used to find the nearest neighbors (frames in the motion database) to the query vector (given input). The result is a set of pre-selected frames for the next best matching frame that is passed on to the narrow-phase. By adjusting the maximum tree depth or the minimum number of frames for the leaf nodes, the resulting number of frames can be adjusted. The bigger the set of frames the broad-phase returns, the more candidates the narrow-phase can choose from, the better the visual quality of the animation but the slower the algorithm.
2. Narrow-phase
Inside the narrow-phase, we iterate through the returned set of frames from the KD-tree, and evaluate and compare their cost against each other. The frame with the minimal cost is the best match that we transition to.
Pseudo-code:
minCost = MAX;
for_all (nearest frames found in the broad-phase)
{
frameCost = 0.0
for_all (features)
{
frameCost += CalculateCost(feature);
}
if (frameCost < minCost)
{
// We found a better next matching frame
minCost = frameCost;
newBestMatchingFrame = currentFrame;
}
}
StartTransition(newBestMatchingFrame);
Character trajectories
Let’s talk about trajectories. A trajectory is a useful way to encode where the character came from and its intention of where and how it wants to move in the future. We store a number of samples containing character positions, as well as facing directions, for a given time window. For example, 4 samples into the past across 0.7 seconds and 6 samples for the desired future trajectory across 1.2 seconds. The Euclidean distances between the samples tell us if the character is accelerating or coming to a stop. The sample locations indicate if the character is moving forward or doing a left turn, and the facing direction gives us more information about if the character is strafing or moving backwards. Recording the past trajectory is easy as we know the current character transform, but how do we decide the future trajectory to generate, and why do we even need that?

Controlling the character
We talked about how the algorithm ensures that the animation is smooth but did not look into how we can actually guide and control our character yet - that is where the trajectory comes in. The motion matching algorithm not only takes a pose but also a desired future trajectory as input. It tries to synthesize an animation that matches the trajectory and makes the character walk onto, or close to, the desired path.
For an interactive game, we can use the gamepad’s joystick position as a target to generate a desired future trajectory by creating an exponential curve starting at the current character position going towards the character facing direction, and then bend the curve towards the joystick’s target position. This process is called trajectory prediction.
Data Analysis & Debugging
While motion matching gets rid of the manual process of setting up locomotion in an animation graph, precisely timing transitions and making sure the blends look good, it also takes away some control. Visualizing data and the state of the algorithm and knowing our data is key for debugging an animation glitch.
O3DE provides a number of debug visualizations to aid troubleshooting. Features like a joint velocity or the trajectory can be visualized together with the query values as well as the feature costs along with some performance metrics. The feature costs over time can be used to see if a visual glitch corresponds with a high cost at that given point in time. A high cost indicates that the algorithm struggled to find a good matching pose for the query. And this again says that our motion database might lack a motion for the given scenario that can be fixed by retaking or adding an extra animation clip.
We also provide data analysis tools to get some insight about what is missing or where we have duplicated animation data. In the middle image below you can see histograms per feature component showing their value distributions across the motion database. They can provide interesting insights, for example, if the motion database is holding more moving forward animations than it has strafing or backward moving animations, or how many fast vs slow turning animations are in the database. This information can be used to see if there is still a need to record some animations or if some types of animation are over-represented and will lead to ambiguity and decrease the quality of the resulting synthesized animation.
The image on the right shows a scatter plot of the features per frame in the motion database. Our multi-dimensional feature data is projected down to two dimensions using principal component analysis . The density of the clusters and the distribution of the samples overall indicate how hard it is for the search algorithm to find a good matching frame candidate. The graph shows what areas are well covered and where we might lack some animation data (Clusters in the image after multiple projections might still be separable over one of the diminished dimensions).

Future Outlook
Research in the field of animation has advanced dramatically over the last several years. Traditional animation techniques are melding together, being replaced or enhanced by data-driven methods and machine learning. Characters are becoming more aware of their environments, automatically reacting to stimuli and are actually now physically present in the world. Control is moving from simple directional input to high-level intentions that automatically adapt to situations. Motion matching is just the start of where we will go with character animation in O3DE!