IN THIS ARTICLE
Scene Graph
The SceneGraph is a bi-directional a-cyclical graph targeting a small number of named entries (maximum of 2 million). It supports both hierarchical and flat iteration over the stored data, either through classic index-based retrieval or through custom iterators. Nodes in the tree can be quickly located through a path-like name that’s composited for all entries.
The Scene pipeline in particular uses the SceneGraph as imported files, such as FBX files, adds substantial additional information about their content, such as meshes, materials, transformations, animations, and so on, by the relation they have to each other. The content often has names associated that have meaning to the artist. For instance, artists are able to identify the shape of a mesh by the name associated with it. The relational information inside these files is usually low in complexity, making the upper limit of 2 million entries more than sufficient. High complexity is often prevented by the format itself and is highly unlikely in the games industry due to dense data not being performant enough in many (DCC) tools. The SceneAPI, however, does value processing speeds as its work is based on loading these files, processing them and exporting to various engine formats. Fast (non-)hierarchical iterations over the SceneGraph and quick look-ups help provide smooth data retrieval.
Notable features
Name indexing
Nodes in the SceneGraph have a name that can be used to locate it at a later time. Names don’t need to be unique although a direct sibling cannot have the same name. When a new node is added its full name is composed as a list of its parent, starting at the root, separated by a dot. As an example, a node with the name “Child” that has a parent called “Parent” would have the full unique name “Parent.Child”. The stored name object returns the full path by calling GetPath, while only the name portion can be returned with GetName.
End points
Nodes can be marked as “end points”. An end point node will not accept children and throws an assert when attempted. The Scene pipeline uses this to mark nodes as being an attribute, for instance. This allows distinguishing a mesh transform from a group transform for instance as they both have the same data, but one is an attribute where the other isn’t. It also makes it easier to iterate over only the attributes of a node and skip over the children that form new groups. What end points exactly means will depend on how the SceneGraph is used, but it always guarantees that end point nodes will not have any children.
Hierarchical and flat retrieval
While the core functionality of the SceneGraph is to provide hierarchical information about nodes, this information is not always needed. Sometimes all that’s needed is a list of the names, or all objects of a certain type. If a tool in the editor for instance needs to present a drop-down list of all bones in a scene, only the names and the content is needed and iterating through them as a flat list is more efficient, yet when the selected bone is exported, the hierarchical information will be needed to find that bones children and attributes. The SceneGraph provides optimal support for both situations, using one or several approaches as needed (more on this later).
Note:Note: while it can be tempting to use the name in some situations to look up the parent, this is both more expensive than a hierarchical lookup and not guaranteed to work in the future.
Guaranteed root node
The SceneGraph is guaranteed to have at least one node. By default, this is a nameless node at the root. This guarantee avoids additional complexities having to deal with the edge case of no nodes. This both helps reduce the API for the SceneGraph and makes it easier to work with as there’s no need for any tests to deal with having no entries. It is something though that has to be kept in mind if a blank root node is not an option. This root node behaves in the same way as other nodes so data and siblings can be assigned to it.
Internal layout
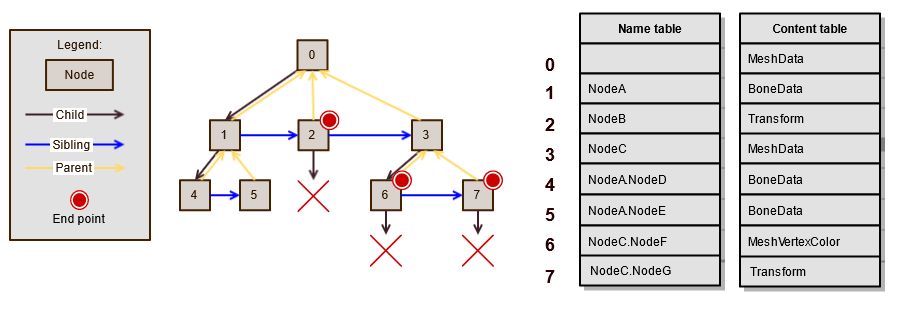
The SceneGraph uses a parent-child-sibling approach to storing the hierarchy, rather than the more common parent-child storage. In this approach the parent doesn’t have a variable sized array to store all the children, instead a single node has a link to its parent, its child and its first sibling. In this context siblings are nodes that that are on the same level and share a common parent. Siblings would be children in a parent-child tree and conceptually are the same as the children of a parent node. The parent-child-sibling approach guarantees a fixed size for all nodes and helps significantly reduce the number of memory allocations required when adding new nodes. In a parent-child tree all nodes will individually allocate memory to hold the children, usually allocating a little more memory to avoid resizing too often (vectors are commonly used in this situation) which results in each node allocating memory as soon as it gets at least one child. In contrast the parent-child-sibling tree has nodes of a fixed size so no additional memory needs to be allocated. As a result, a single array of nodes is sufficient, which would only need to allocate memory when the array needs to be resized for additional nodes. Because the nodes are stored in the same array they also exhibit better memory locality while the individual children array of a parent-child tree could be highly spread out in a worst-case scenario. The downside can be that siblings don’t live close together in memory as they would in the traditional parent-child approach, which can lead to many jumps in memory when traversing over the graph. However, when the SceneGraph is used with scene files the hierarchy usually doesn’t change after loading, avoiding this problem to a large degree.
The common memory overhead associated with the parent-child-sibling approach is avoided by packing parent, child and sibling index into 64-bits for the hierarchical information, though at the cost of limiting the number of available indices to about 2 million. Further memory reduction is achieved avoiding storing pointers to the name and content associated with the node, but instead storing a 32-bit index into the Name and Content tables.
Querying and navigating
There are few ways that the SceneGraph can be traversed based on the custom logic needed to make product assets.
Index based traversal
The most direct way to work with the SceneGraph is to use the index-based API, which is based around querying for an index and using the index to get information about the node. Getting an index can be done through “Find” to search for an index by name or simply by calling “GetRoot” to get the root index and walking down the hierarchy. Information about the node can be obtained through several index-based functions such as “GetNodeName”, “HasNodeContent” or “IsNodeEndPoint”. Navigating to the next node in the hierarchy can be done by calling “GetNodeParent”, “GetNodeChild” or “GetNodeSibling”. Always make sure to check if the returned index is valid by calling “IsValid()” on it to determine if the end of a chain has been reached.
The benefits of the index based is that it’s straightforward and easily accessible. It’s also the most complete api, as the iterator approach has limitations out of necessity, for instance the iterator approach doesn’t allow for adding new nodes. It can also be faster in some situations, most notably finding an entry by name will be significantly faster using the index-based approach.
The downsides however are that for more extensive usage, in particular when navigating the full tree, it involves having to write a lot more boilerplate code that the iterators provide out of the box. The index-based approach currently also only provides support for hierarchical navigation and doesn’t allow for flat iteration over the data.
Index example:
// Print all attributes the crate mesh has.
NodeIndex current = sceneGraph.Find("CrateMesh");
if (current.IsValid())
{
current = sceneGraph.GetNodeChild(current);
}
while (current.IsValid())
{
if (sceneGraph.IsNodeEndPoint(current))
{
AZ_TracePrintf("Attribute: %s\n", sceneGraph.GetNodeName(current).c_str());
}
current = sceneGraph.GetNodeSibling(current);
}
Iterator based traversal
Besides index based access, the content of the SceneGraph can be accessed through iterators which behave much like iterators from common containers such as AZStd::vector or AZStd::unordered_map. To reduce the number of functions to deal with, the begin and end iterator are combined into a “view”. Besides reducing the number of functions, views also allow the use of ranged for-loops without the need for additional wrapper classes. For convenience all the iterators that are part of the SceneGraph provide utility functions in the form of Make<iterator>View to easily construct views.
Non-hierarchical
Though the basic principle of the SceneGraph is to store content in a hierarchical fashion, situations where simple access to just the values are needed are not uncommon. For these situations the SceneGraph allows flat access to:
- Stored content (GetContentStorage)
- Stored names (GetNameStorage)
- Hierarchical information (GetHierarchyStorage)
These lists can be individually iterated over, but if multiple values are required, such as the name and the content, consider using the PairIterator to combine them. For filtering the FilterIterator can be used which can use any function to apply filtering, but for convenience it’s often easier to use the TypeFilter structs. Use ExactTypeFilter when filtering for an exact type of class or DerivedTypeFilter when searching for any classes derived from the provided IManifestObject or IGraphObject. These two iterators and utility structs can also be used when working with the SceneManifest.
Non-hierarchical iterator:
// Print all the names used in the graph
NameStorageConstData names = sceneGraph.GetNameStorage();
for( const std::string& name : names )
{
AZ_TracePrintf( "Graph elements: %s\n", name.c_str());
}
// Collect all selected meshes.
auto content = sceneGraph.GetContentStorage();
auto view = SceneContainers::Views::MakePairView(names, content);
AZStd::vector<AZStd::shared_ptr<SceneDataTypes::IGraphObject>> selectedMeshes;
for (auto& iterator : view)
{
if (IsMeshSelected(iterator.first.c_str()))
{
selectedMeshes.push_back(iterator.second);
}
}
Hierarchical based traversal
The SceneGraph provides hierarchical iteration through tree iterators:
- SceneGraphUpwardsIterator to navigate from a node to the root.
- SceneGraphDownwardsIterator to move downwards from a given node either breadth-first or depth-first.
- SceneGraphChildIterator to list all direct children of a node.
Using these iterators greatly simplifies the management normally required for iterating over a graph while presenting the iteration as a flat list. These iterators take either a node index or a hierarchical iterator (returned by GetHierarchyStorage) and an iterator to represent the returned values (usually the names, the content or a combination of the two). If the hierarchical iterator or node index doesn’t start at the root but the given iterator does start at the root, the iterator can be automatically moved to the correct position by setting the “rootIterator” boolean to true.
Hierarchical upwards iteration example:
auto content = sceneGraph.GetContentStorage();
auto view = SceneViews::MakeSceneGraphUpwardsView(graph, nodeIterator, content.cbegin(), true);
for (const auto& node : view)
{
if (node)
{
const SceneDataTypes::ITransform* nodeTransform = azrtti_cast<const SceneDataTypes::ITransform*>(node.get());
if (nodeTransform)
{
transform = nodeTransform->GetMatrix() * transform;
}
}
}
Hierarchical downwards iteration example:
auto names = sceneGraph.GetNameStorage();
auto content = sceneGraph.GetContentStorage();
auto pairView = MakePairView(names, content);
auto view = MakeSceneGraphDownwardsView<BreadthFirst>(sceneGraph, sceneGraph.GetRoot(), pairView.cbegin(), true);
for (const auto& iterator = view.begin(); iterator != view.end(); ++iterator )
{
uint64_t parentIndex = itertator.GetHierarchyIterator()->m_parentIndex;
bool isMesh = iterator.second->RTTI_IsTypeOf(IMeshData::TYPEINFO_Uuid());
QIcon& icon = isMesh ? GetMeshIcon() : GetDefaultIcon();
uiTree[parentIndex].AddChild(iterator->first.c_str(), icon);
}
// Check if a node has an animation data attribute.
auto content = sceneGraph.GetContentStorage();
auto view = MakeSceneGraphChildView<AcceptEndPointsOnly>(graph, nodeIterator, content.begin(), true);
auto result = AZStd::find_if(view.begin(), view.end(), DerivedTypeFilter<IAnimationData>());
return result != childView.end();
Moving between index and iterator
On occasion iterators are doing part of the work but the final steps require an index and sometimes it’s the other way around. For these scenarios the SceneGraph provides a few conversion functions to convert any of the base iterators to a node index (ConvertToNodeIndex) or to convert a node index to a hierarchy iterator (ConvertToHierarchyIterator). Note that in order to use these in a loop the iterator itself is required, which means this can’t be used in combination with ranged for-loops.
NodeHeader and NodeIndex
Rather than using plain 64-bit and 32-bit integers, hierarchical information and indices are store in NodeHeader and NodeIndex respectively. Even though these are objects, its advised to pass these by value as this is faster than by reference.
The node hierarchy is stored in 64-bits, where 21-bits are used for the index to the parent, child and sibling making a total of 63 bits used. The final bit is used to indicate whether or not the node is an end-point. The node header provides these as bit-fields and has a few utility functions for basic status queries.
The NodeIndex is used to more specifically encode the principle of an graph index by limiting certain abilities such as various comparisons. It’s also deliberately less clear how to create a new NodeIndex, promoting the usage of the SceneGraph and avoiding some common invalid index problems.